AMCL定位
概述
代码实现
一些概念
粒子/样本
一个位姿和权重。
cluster/聚类
表示一些位置比较接近的粒子的统计信息,包括聚类的粒子个数,包含的粒子的权重和,均值和 协方差,区域。
kdtree
包含root节点地址,节点个数和最大数量,节点地址,叶子节点个数。 每个node包含叶子和深度,转轴维数编号,节点key,value,cluster标签,两个子nodes。
集合set
set里面包含samples和cluster的信息,同时还包括该集合总的粒子个数,所有粒子的 指针,一个用来保存粒子位置的kdtree,cluster的个数/最大个数,cluster的指针, 统计信息包括所有粒子的位置均值和协方差,收敛情况。
粒子滤波器pf
包含最大最小粒子个数限制,用于调整粒子个数的参数,当前使用的两个set和活跃的 set编号,采样函数和采样需要的地图数据,用于判断收敛情况的距离值及最终的收敛情况。
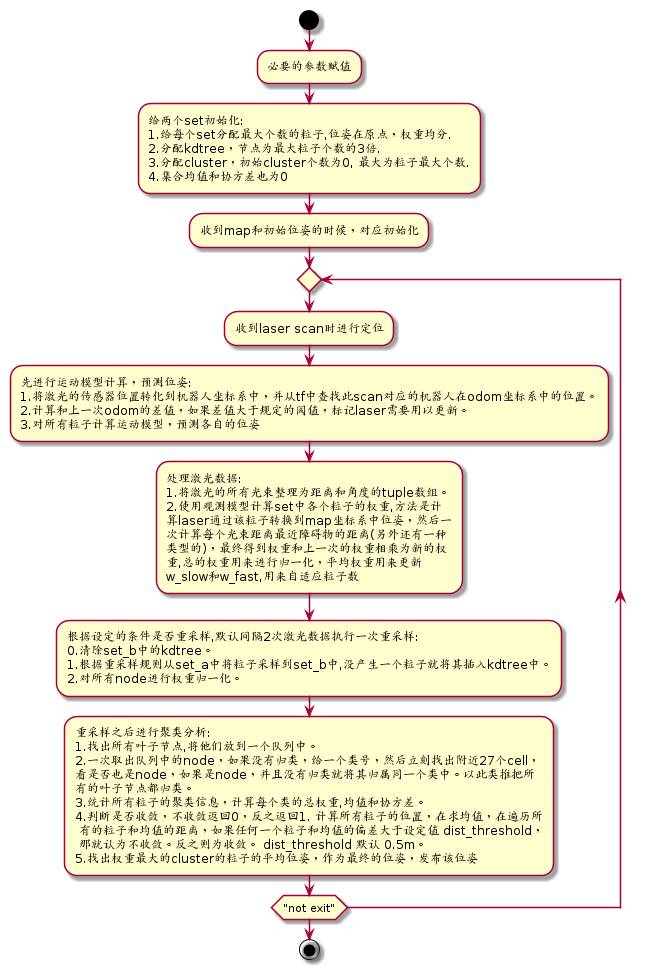
流程图
初始化滤波器流程图:
理解
kdtree是如何插入的?
首先我们要知道,amcl中有两个set 来保存粒子和聚类。每次重采样就会激活另一个set, 将粒子从原来的集合中复制到新的set中。具体插入是怎么做的呢?
首先将位姿通过分辨率转换成一个整数。然后执行插入,返回node左右kdtree的root。
void pf_kdtree_insert(pf_kdtree_t *self, pf_vector_t pose, double value) { int key[3]; key[0] = floor(pose.v[0] / self->size[0]); key[1] = floor(pose.v[1] / self->size[1]); key[2] = floor(pose.v[2] / self->size[2]); self->root = pf_kdtree_insert_node(self, NULL, self->root, key, value);将节点插入kdtree.
pf_kdtree_node_t *pf_kdtree_insert_node(pf_kdtree_t *self, pf_kdtree_node_t *parent, pf_kdtree_node_t *node, int key[], double value) { int i; // 用来记录维度信息,也就是转轴。 int split, max_split; // 用来记录当前节点和上一个节点各个维度的差值。 /* 分三种情况: * 1. node为空的时候: 这时候要么是kdtree的第一个插入的node;要么是在叶子节点上 * 插入新的节点(这时候会将该节点返回作为上一层节点的子节点,这样就建立了父子关 * 系); * 2. node是叶子节点的时候: 直接在该节点下插入新节点,同时复制当前节点作为另一 * 个子节点; * 3. node不为空,但不是叶子节点,也就是说是枝节点,这时候要继续往子节点出插 * 入,但是可能下一级还是有节点,就有可能递归的继续再往下插入了直到称为叶子节 * 点。 */ if (node == NULL) { /* 1. 当这个这个kdtree第一次插入的时候,node就是空的。 * 2. 后面要在参数node下插入叶子节点的时候也是空的。 */ assert(self->node_count < self->node_max_count); node = self->nodes + self->node_count++; memset(node, 0, sizeof(pf_kdtree_node_t)); // 每个node的leaf只会是0和1,1表示是叶子节点,当在该节点插入子节点之后就变为0. node->leaf = 1; if (parent == NULL) { node->depth = 0; } else { node->depth = parent->depth + 1; } for (i = 0; i < 3; i++) { node->key[i] = key[i]; } node->value = value; self->leaf_count += 1; } else if (node->leaf) { // If the node exists, and it is a leaf node... // If the keys are equal, increment the value if (pf_kdtree_equal(self, key, node->key)) { node->value += value; } else { // The keys are not equal, so split this node // Find the dimension with the largest variance and do a mean // split max_split = 0; node->pivot_dim = -1; for (i = 0; i < 3; i++) { split = abs(key[i] - node->key[i]); if (split > max_split) { max_split = split; node->pivot_dim = i; } } assert(node->pivot_dim >= 0); node->pivot_value = (key[node->pivot_dim] + node->key[node->pivot_dim]) / 2.0; /* 返回新节点的指针为该节点的子节点。这样建立父子关系。 */ if (key[node->pivot_dim] < node->pivot_value) { node->children[0] = pf_kdtree_insert_node(self, node, NULL, key, value); node->children[1] = pf_kdtree_insert_node(self, node, NULL, node->key, node->value); } else { node->children[0] = pf_kdtree_insert_node(self, node, NULL, node->key, node->value); node->children[1] = pf_kdtree_insert_node(self, node, NULL, key, value); } node->leaf = 0; self->leaf_count -= 1; } } else { // If the node exists, and it has children... assert(node->children[0] != NULL); assert(node->children[1] != NULL); if (key[node->pivot_dim] < node->pivot_value) { pf_kdtree_insert_node(self, node, node->children[0], key, value); } else { pf_kdtree_insert_node(self, node, node->children[1], key, value); } } return node; }
叶子节点的个数意味着什么?
没插入一个节点,叶子节点就会增加一个,但是并不是有多少粒子就有多少叶子节点, 因为在插入的时候会将粒子的位姿计算在一定的分辨率内的整数结果,如果一样就只会 将权重相加,而不是新增节点。这样只有在粒子分散很大的时候,叶子节点才会很多, 因此叶子节点越少说明定位结果越收敛。
如何判断是否收敛?
计算所有粒子的位置,在求均值,在遍历所 有的粒子和均值的距离,如果任何一个粒子和均值的偏差大于设定值 dist_threshold, 那就认为不收敛。反之则为收敛。 dist_threshold 默认 0.5m。
实际使用的问题
- 粒子数目太多造成重采样的时候,插入node时需要很长时间,导致长时间卡在这里,无 法发布位姿,造成导航等出现问题。所以粒子数也不能盲目增加,amcl默认是100~5000, 后来被改成了3000到5000,因此导致隔一段时间就卡一次。