Kafka使用
部署和使用
一个生产的配置
# ZooKeeper zookeeper.connect=[list of ZooKeeper servers] # Log configuration num.partitions=8 default.replication.factor=3 log.dir=[List of directories. Kafka should have its own dedicated disk(s) or SSD(s).] # Other configurations broker.id=[An integer. Start with 0 and increment by 1 for each new broker.] listeners=[list of listeners] auto.create.topics.enable=false min.insync.replicas=2 queued.max.requests=[number of concurrent requests]
升级
集群之间迁移数据
> bin/kafka-mirror-maker.sh --consumer.config consumer.properties --producer.config producer.properties --whitelist my-topic
扩大集群
- 添加broker到集群很简单,就是分配一个独立的broker id并启动即可(connect同一个zk的都属于同一个cluster)。
- 新增的broker不会自动分配任何数据的分区,除非分区本移动到新broker上,否则如果没有新的topic创建,他就什么也不做, 因此需要迁移已有数据到新broker上。
监控
- 建议监控服务器端的GC time,CPU使用,IO服务时间等。
- 建议监控客户端的全局的和单个topic的消息byte rate,
开始的问题
一开始听人说 kafka 是一个很牛逼的消息系统,所以有下面的一些问题,带着问题去看可能好一点。
- kafka 和其他消息队列有什么不同
目前市面上有好些消息系统,比如 RabbitMQ,Redis,ZeroMQ,ActiveMQ,Kafka/Jafka,他们各有什么特点, kafka 和他们有什么不同的地方?
- 为什么他的吞吐这么牛逼
kafka 的消息吞吐量可以达到 10W/s,为什么会有这样的能力?
- 整套系统的框架
kafka 有 Broker,Producer 和 Consumer,以及一个对整体进行管理的 Zookeeper,他们各自扮演什么角色, 又是怎么联系起来的?
- 如何使用
最后就是怎么使用这个东西?怎么监控它的运行情况?
kafka 概要
先要明白几个和消息相关的概念,明白这些概念也就对整体有个了解了:
- 话题 Topic
Topic把Kafka中流通的消息进行分类, 它算是消息的载体。生产者把消息发送到对应的Topic上,消费者从这个 Topic获取消息进行处理。和其它大部分系统的topic一样,一个topic可以被0,1或者多个订阅者订阅使用。但 不同的是:在比如mqtt,rabbitmq等broker中,一个topic上同时只能有一条消息,后面的消息会把前面的消息 覆盖,但是kafka中的消息则会被保留起来,类似数据库,但是毕竟是一个broker,数据不可能一致留着占用资 源,因此可以通过设置消息产生时间期限和消息的数量大小限制来删除旧的消息。
- 分区 Partition
由于 kafka 中 topic 的特殊性,一个topic可能会接收到来自生产者的大量的消息,所以一个topic会承受很 大的压力, 因此在创建一个topic的时候会指定把这个topic分成几个区(Partition),每个分区都有在这个 topic粒度上 的唯一编号,Producer 在发送消息的时候会由Producer对消息做 某种决策(或者说路由分流) , 将这条消息归到某个分区。topic 的分区如下图所示。
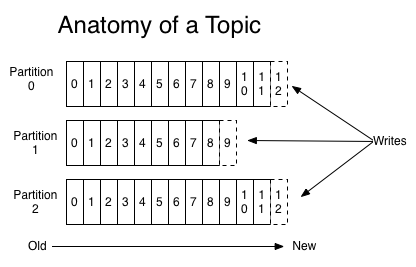
Figure 1: Topic Partitions
Producer 确定某条消息该发往哪个Partition 的方法主要有两种 ,一个是随机确定,另一个是通过消息的一 个key来利用hash算法确定,通常的做法是 (hash(key) rem partition_num) 的结果作为选择的分区(所以 Producer首先要知道共有多少分区, zookeeper负责该功能)。这样通过分区就可以实现负载均衡, 增加kafka 的读写能力。
- 分段 Segment
每个broker上 给每个Partition都会产生一个目录 ,该目录下面保存这发往这个分区的消息。消息是按照顺 序存入磁盘的,但并不是作为一个文件保存在这个目录下面的,而是 分段保存成一个个文件(segment 文件) , 每个segment以该segment的第一条消息的offset命名, 比如第一个文件是00000000000000000000.log,下一个 文件接着该文件最后一条消息的偏移往下排。kafka 中可以设置一些参数来控制 什么时候新建segment , 什么时候删除旧的segment , 后台会有线程隔多久检查一次 ,决定相关的处理。Partition 内的segment 如下图所示。
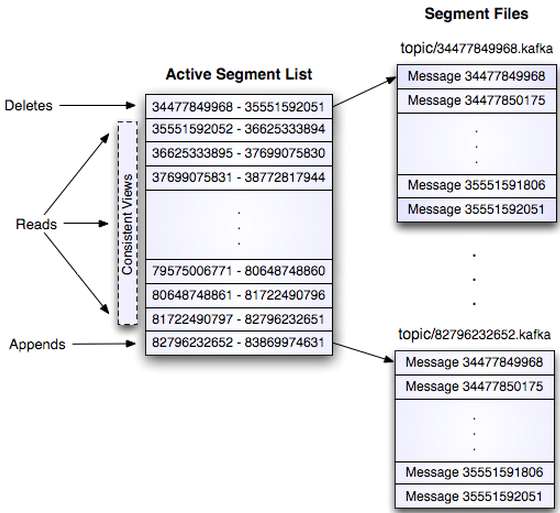
Figure 2: Topic partition 内的分段 segments 文件结构示例
- 顺序写磁盘
Kafka是通过顺序写磁盘来持久化数据的,一般来说磁盘的操作效率是很低的,肯定很难得到这么高的吞吐量,但是 有人测试过顺序写磁盘有时候比随机写内存还要快。这种 顺序写磁盘的方式正式kafka高吞吐的一个重要原因 。
kafka 给每条消息都会置一个相对这个Partition第一条消息的偏移(offset) 。给每一条消息都编号并按顺序append 到上一条消息后面,这也方便Consumer更方便地消费数据。
- 消费方式 push vs pull
大部分消息系统的消费有两种方式:push vs pull。前者是服务器一有消息就直接推送给Consumer,不管 Consumer 目前有没有能力处理;pull则是Consumer有能力处理的时候自动向broker拉取消息,如果broker没有消息就会等待 消息的到来。 kafka的设计是生产者向broker push消息,而消费者向broker pull消息 。这样消息的使用决定权在 Consumer,所以不太会因为消息压力太大把Consumer搞挂。
同时,由于消息存储的时候有一个offset值, Consumer消费的时候也可以维持消费到的offset值,按顺序消费 , 这样消费速度就会更快。当然如果消费者想消费已经消费过的消息,只要Consumer改变这个值就可重复消费了。
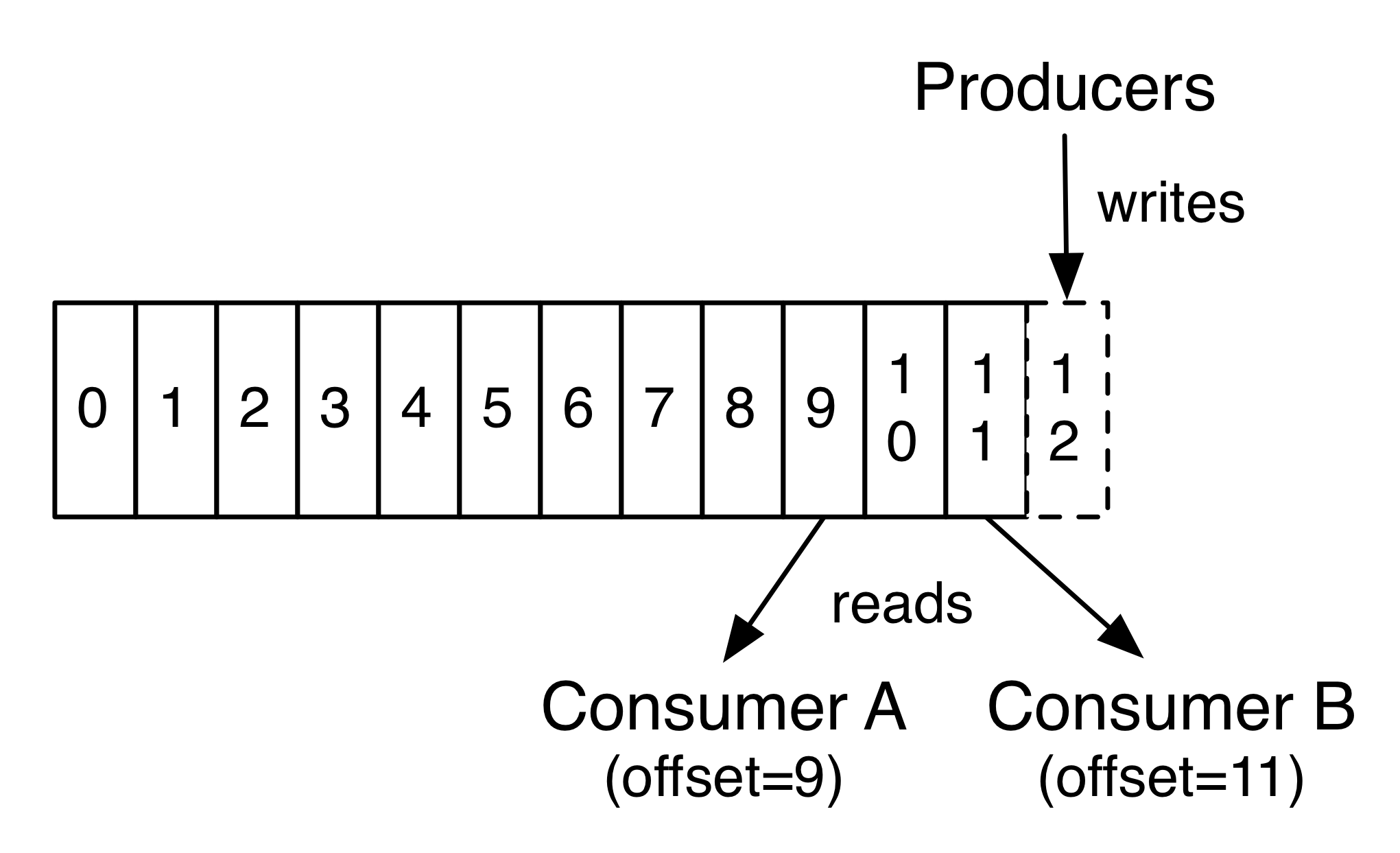
Figure 3: Consumer 带 offset 消费消息
- 消费组 Consumer Group
kafka通过消费组把Consumer归在某些组里面,实现broker上消息对Consumer的单播和广播。 原则是一条消息只 要被一个组里面的一个 Consumer 消费,就不会再给这个组的其他成员了 。这样如果我们要对所有Consumer 广播,那就 他们单独成一个组,如果单播,就把多个 Consumer 放在一个 Group 里面。
- 复本集 Replicas
为容错性考虑,避免因为一个 broker 挂了就无法正常工作的情况,通常在使用时会将多个broker布置为一个cluster。 首先,这种考虑可以真正的实现负载均衡,让多个broker来分担压力;其次,一个Partition写到一个broker上, 一旦这个broker挂了,数据就可能丢失了。因此kafka 在Partition粒度上设置复制集 。我们在建立topic的时候也 会设置一个Replicas个数的参数,那么这个 topic 的所有分区都会有这么多个副本(注意并不是所有broker上都有所有 Partition的副本),而且这些副本分散在不同的broker上,即使一个broker挂了或者不工作了,还有另外的broker保存 相同的数据,可以保证数据不丢失。
一个 Partition 的所有副本集中 有一个是leader,其他是follower。 Producer向cluster推送消息和Consumer从 broker拉取消息都只和leader交互 , 然后follower像Consumer消费数据一样从leader上拷贝数据 。
- In-Sync Replicas (ISR)
和大部分分布式系统一样,要自动处理故障就必须对一个节点node的"alive"有一个精确的定义。kafka的存活node(也就 是In Sync node)需要满足两个条件:
| 1 | node必须和zookeeper之间通过心跳维持session |
| 2 | slave node必须复制leader上发生的写操作,并且不会落后leader太远 |
leader会跟踪Partition的ISR集合(就是一个记录In Sync的列表),如果某个follower挂了或者同步数据落后了,leader就 会把这个node从ISR列表中删除, 确定node挂了或者数据落后由参数replica.lag.time.max.ms确定。
如果一条消息被所有ISR节点写入各自的log,那么这个消息就是commited的消息,只有这样的消息才会给Consumer使用 , 也就是说Consumer看到的消息一定不会因为leader失效而丢失; 另一方面,用户可以设置是否让Producer等待它发送的 消息被标记为commited (request.required.acks设置),这就需要在数据延迟和数据持久性上做出权衡了(做法是通过Producer使用ack来判断)。
Producer把一条消息发送到该Partition的leader之后,只有所有ISR都把这条消息写入log,然后给出ack确认之后这条消 息才叫commited的,此外leader的最后一条消息的offset叫做log end offset(LEO)。 当一个ISR的offset和leader的 LEO差值大于某个值(通过replica.lag.max.messages设置)时,这个broker就会被从ISR列表中剔除。 此时follower还 可以从leader上复制数据(其实就是消费数据),当数据差值符合条件是还会被添加到ISR列表中.
需要注意的是ISR的数量并不是和该Partition的Replicas个数一样的,ISR数量是可以配置的, 这样就只需要有这个数量 的副本集对消息进行确认,消息才能认为是commited的。
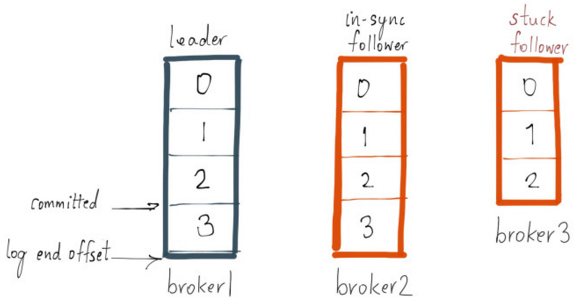
Figure 4: ISR 确认消息
- Kafka 对消息投递的保障
kafka 提供消息投递过程中的一些保证:
| 1 | 发送到同一个 partition 的消息会按序加在前一条消息后面。 |
| 2 | 消费者会按序得到保存的消息 |
| 3 | 对于 replication factor 为 N 的 topic,我们可以实现 N-1 个服务器故障而不丢失任何提交的数据。 |
- 如何管理整个系统--zookeeper
它是一个快速、高可用、容错、分布式的协调服务。你可以使用 ZooKeeper 构建可靠的、分布式的数据结构,用于群组 成员、leader选举、协同工作流和配置服务,以及广义的分布式数据结构如锁、队列、屏障(Barrier)和锁存器(Latch)。 许多知名且成功的项目依赖于 ZooKeeper,其中包括 HBase、Hadoop 2.0、Solr Cloud、Neo4J、Apache Blur(Incubating) 和 Accumulo。
Kafka将元数据信息保存在Zookeeper中,但是 发送给Topic本身的数据是不会发到Zk上的 ,否则Zk就疯了。 kafka 使用zookeeper来实现动态的集群扩展 ,不需要更改客户端(producer和consumer)的配置。 broker会在zookeeper 注册并保持相关的元数据(topic,partition信息等)更新 。 而 客户端会在zookeeper上注册相关的watcher 。一 旦zookeeper发生变化,客户端能及时感知并作出相应调整。 这样就保证了添加或去除broker时,各broker间仍能自动 实现负载均衡。这里的客户端指的是Kafka的消息生产端(Producer)和消息消费端(Consumer), Producer端使用zookeeper 用来"发现"broker列表 ,以及和Topic下每个partition的leader建立socket连接并发送消息。也就是说每个Topic的partition 是由leader角色的Broker端使用zookeeper来注册broker信息,以及监测partition leader存活性。 Consumer端使用 zookeeper用来注册consumer信息 ,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partition leader 建立socket连接,并获取消息。
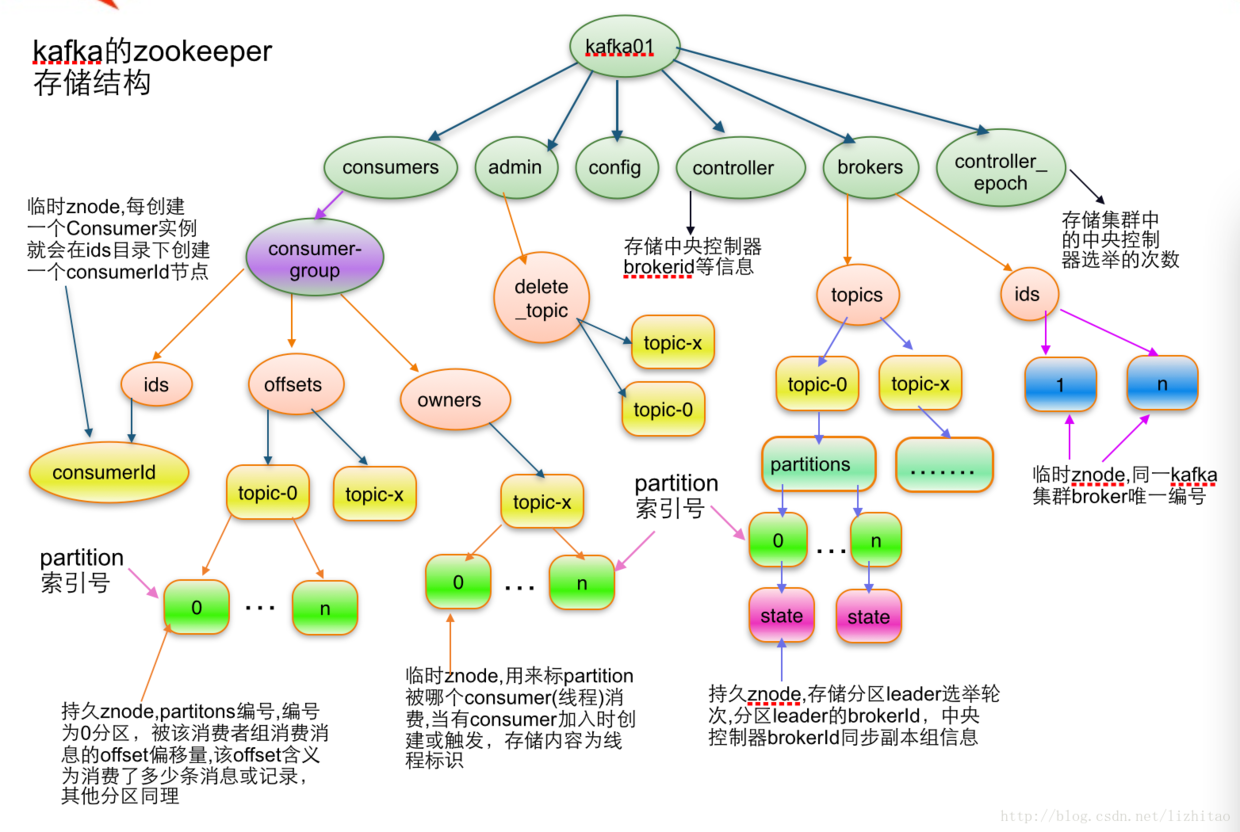
Figure 5: zookeeper中的信息
安装
kafka 需要 java-jdk 提供支持,同时还需要 zookeeper 来对集群进行管理。因此需要安装这些东西。
安装 java jdk
- 在这里 下载 Linux 的 jdk,根据 Linux系统的位数选择,这里以后缀为.tar.gz的为例,.rpm的直接安装就是。
- 解压。
- 把解压后的文件夹放到/usr/local 下面。(这个随便,任意目录下都可以)
- 在主目录下找到隐藏文件.profile , 若没有.profile,则去找文件 .bash_profile (注意文件名以点号开头,因为是隐藏文件)。
- 在文件.profile 或 .bash_profile 中添加环境变量,在文件的最末尾加上以下4行(需根据具体情况修改,由JAVA所在目录决定):
export JAVA_HOME = /usr/local/jdk1.8.0
export JRE_HOME = ${JAVA_HOME}/jre
export CLASSPATH = .:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH = ${JAVA_HOME}/bin:$PATH
若添加正确,注销或重启计算机以后,在Bash Shell中输入:
$ java -version $ javac -version
都会显示版本信息。
安装 zookeeper
在zookeeper 这里下载最新的 zookeeper 二进制文件,解压之后即可使用。
安装 kafka
在这里 选择最新版本的 kafka 二进制文件包下载,解压到你的某个文件即可使用。
使用概况
Kafka 作为 messaging system
传统的消息系统有两种模式:queuing 和 publish-subscribe。 在 queuing 中,Consumer 池子中只有一个 Consumer 能得到这个消息,他得到消息之后,消息就会被删除,其他 Consumer 无法获得;而 publish-subscribe 模式则是所有 订阅的 Consumer 都会收到同样的消息。Kafka 引入了 Consumer Group 的概念可以同时实现上面两种类型。
此外,kafka 相比传统的消息系统在时序方面有较强的保证。传统的队列在服务器端按序保存消息,多个消费者从这个 队列取消息的时候,尽管服务器是按是按顺序给出的,但是消息是异步投递给消费者的,所以他们可能不会按顺序到达不同的 消费者,这意味这在并行处理的时候消息还是会混乱。于是小系统常常通过一种叫"独占消费"(exclusive consumer)的 变通方式来允许一个进程消费一个队列,这也就不是并行处理了。Kafka 在这方面做的很好,他通过 topic 分区 partition 的概念来实现在分区内部的时序。这样我们可以确保某个Consumer是这个partition的唯一reader,自然就可以按时序消 费消息。但是注意,消费者的个数不能高于partition的个数。
Kafka 作为 storage system
消息队列可以作为一个飞行消息的存储系统,通过保存消息可以把消息的发布和消费进行解耦。Kafka是一个好的存储系统, 他有什么不同呢?
数据写入 kafka 是写入到磁盘的,同时为了实现容错而进行复制。kafka 允许 producers 等待 ack 确认消息,这样只有当 这条消息被完全复制才会任务消息写入完成,这样就保证了持久化。前面已经讲到,kafka的按序存储方式决定了他的操作和 数据的大小没有关系。
Kafka 作为消息处理系统
只有消息的读写和存储有时候还不够,还需要实现消息的实时处理。Kafka 是一个消息流处理器。它从输入 topics 上获得连续的 数据流,执行一些处理之后产生连续的数据流到输出 topics。
虽然我们可以使用 producer APIs 和 Consumer APIs 直接直线一些简单的处理,但是对于一些复杂的转换,Kafka 提供了 完整的 Streams API。这样就可以构建一个运用,不需要处理繁琐的步骤。
使用例子
The Log: What every software engineer should know about real-time data's unifying abstraction
为了对使用有一个了解,我们设置三个节点的集群(单节点的集群就略过了),首先要启动三个 server 节点: 复制 config/server.properties 文件为 config/server-1.properties,config/server-2.properties,修改如下:
config/server.properties: broker.id=0 listeners=PLAINTEXT://:9092 log.dir=/tmp/kafka-logs config/server-1.properties: broker.id=1 listeners=PLAINTEXT://:9093 log.dir=/tmp/kafka-logs-1 config/server-2.properties: broker.id=2 listeners=PLAINTEXT://:9094 log.dir=/tmp/kafka-logs-2
然后要启动 zookeeper 后再启动这三个节点:
$./bin/zookeeper-server-start.sh config/zookeeper.properties [2016-11-08 15:12:28,204] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig) ...... $ bin/kafka-server-start.sh config/server.properties $ bin/kafka-server-start.sh config/server-1.properties $ bin/kafka-server-start.sh config/server-2.properties
启动完成之后我们创建一个 topic/队列, 名为 v1-r3-p3, 并给这个 topic 设定三个复制集,3 个 partitions:
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic v1-r3-p3
现在我们看看三个节点各自扮演什么角色:
$ ./bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic v1-r3-p3 Topic:v1-r3-p3 PartitionCount:3 ReplicationFactor:3 Configs: Topic: v1-r3-p3 Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2 Topic: v1-r3-p3 Partition: 1 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0 Topic: v1-r3-p3 Partition: 2 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
第一行指出这个 topic,有 3 个 partitions,3 个复制集。后面每个 partition 的情况,有多少 partition 就有多少行。 Replicas 是三个复制集,Isr 是"in-sync" replicas,两者的区别是,后者是前者的子集,Isr 只是当前活着的节点。
根据上面的信息,结合上一节的说明,节点 0 是 v1-r3-p3 的 partition 0 的 leader,同时是 partition 1 和 2 的 follower, 消息的 Producer 只和节点 0 交互,将数据写到节点 0,然后节点 1 和 2 会被动地从节点 0 复制数据。同理,另外两节点也各自 作为 partition1,2 的 leader,同时是其他两个的 follower。
下面我们启动一个 producer 和一个 Consumer:
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic v1-r3-p3 $ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic v1-r3-p3
在 Producer 窗口我们可以输入一行内容,回车之后 Consumer 中可以显示出来。
此外在三个节点的 log 目录:/tmp/kafka-logs, /tmp/kafka-logs-1, /tmp/kafka-logs-2 目录下面我们会看到三个分区的目录:
| v1-r3-p3-0 |
| v1-r3-p3-1 |
| v1-r3-p3-2 |
这里就只有一个是该节点作为主节点的分区内容,另外两个目录都是从该分区的 leader 上复制来的。
每个目录下面:
| 00000000000000000000.index |
| 00000000000000000000.log |
| 00000000000000000000.timeindex |
00000000000000000000.log 就是 segment 文件,在配置文件中我们设置了单个 segment 文件的大小,超过这个大小就会创建新的 segment 文件
接下来我们检验一下他的容错性,我们知道 Broker0 是 partition0 的 leader,如果我们把它杀死,会怎么样呢?
$ ps aux | grep server.properties root 24241 0.0 0.0 72700 2336 pts/32 S+ 15:48 0:00 sudo ./bin/kafka-server-start.sh config/server.properties $ sudo kill 24241 $ bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic v1-r3-p3 Topic:v1-r3-p3 PartitionCount:3 ReplicationFactor:3 Configs: Topic: v1-r3-p3 Partition: 0 Leader: 1 Replicas: 0,1,2 Isr: 1,2 Topic: v1-r3-p3 Partition: 1 Leader: 1 Replicas: 1,2,0 Isr: 1,2 Topic: v1-r3-p3 Partition: 2 Leader: 2 Replicas: 2,0,1 Isr: 2,1
现在我们看到原本 Partition0 的 leader 是节点 0,现在变成了节点 1 了,Replicas 还是没有变,但是 Isr 变了,杀死的节点 不在了。
但是 Producer 和 Consumer 依然工作的很好,尽管他们启动的时候指定的端口是节点 0 的端口。
Kakfa 的监控
目前对 kafka 的监控程序有好几个,
| 1 | KafkaOffsetMonitor | This is an app to monitor your kafka consumers and their position (offset) in the queue. |
| 2 | Availability-Monitor-for-Kafka | Availability monitor for Kafka allows you to monitor the end to end availability and latency for sending and reading data from Kafka. |
| 3 | kafka-web-console | This project is no longer supported. Please consider Kafka Manager instead. |
| 4 | kafka-monitor | Kafka Monitor is a framework to implement and execute long-running kafka system tests in a real cluster. |
| 5 | kafka-manager [Yahoo] | A tool for managing Apache Kafka. |
前几个都没怎么更新了,比较新的是 kafka-monitor 是 LinkIn 支持的,kafka-manager 是 yahoo 支持的. 但是前者功能目前还很不完善。 这里使用雅虎的 kafka-manager。
如果想要获得更详细的监控信息,需要在启动kafka的时候打开JMX端口,在kafka-manager创建集群的时候也打开JMX Polling。 在 kafka-server-start.sh中修改为:
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export JMX_PORT="9999"
fi
就是加上export JMX_PORT="9999"
- 需要事先安装 java 环境。
$ git clone https://github.com/yahoo/kafka-manager.github $ ./sbt clean dist #这个过程需要花费很长时间下载很多东西。
安装完之后会产生安装二进制包,在 target/universal 文件夹里面,是一个 zip 文件包。 解压这个 zip 文件,修改 conf/application.conf 文件。
kafka-manager.zkhosts="localhost:2181"
kafka-manager.zkhosts=${?ZK_HOSTS}
指定 zookeeper 的 ip 和 host,如果不想硬编码,可以设置环境变量 ZK_HOSTS="localhost:2181"
- 启动
$ ./bin/kafka-manager # 如果要使用特定的配置文件或者打开特定的端口可以使用下面的命令(默认端口是 9000): $ ./bin/kafka-manager -Dconfig.file=/path/to/application.conf -Dhttp.port=8080 # 如果 java 的路径不在 path 中,可以如下制定 $ bin/kafka-manager -java-home /usr/local/oracle-java-8
完了就可以使用浏览器查看了。
- 新建 cluster
进入添加 cluster 界面,给集群一个命令,然后把 cluster 的 zookeeper 的 host 填好, 如果使用了多个 zookeeper,可以使用逗号隔开:
localhost:2181
- 可以新建 topic
- 参数含义
preferred replica: 每个 partitiion 的所有 replicas 叫做"assigned replicas","assigned replicas"中的 第一个replicas叫"preferred replica",刚创建的topic一般"preferred replica"是leader。
重要的配置说明
kafka配置
必须要的配置:broker.id, log.dirs, zookeeper.connect
| 参数名 | 默认 | 说明 |
|---|---|---|
| broker.id | 0 | 该kafka node在集群中的唯一标识。如果没设置则自动根据reserved.broker.max.id + 1产生。 |
| advertised.host.name | 替换为advertised.listeners, 只有当advertised.listeners or listeners没有设置的时候才有用。 | |
| advertised.port | 替换为advertised.listeners, 只有当advertised.listeners or listeners没有设置的时候才有用。 | |
| advertised.listeners | 这个listener会发布到zookeeper,然后client通过这个listener来连接broker, 如果未设置该项,默认将使用参数listener。在IaaS环境中,这个地址应该和broker绑定的地址不一样。 | |
| auto.create.topics.enable | true | 是否允许服务器自动创建topics。 |
| auto.leader.rebalance.enable | true | 后台进程会定期检查并按需要触发leader的再平衡。 |
| background.threads | int(10) | 用于各种后台任务的线程个数。 |
| compression.type | string(producer) | ('gzip', 'snappy', 'lz4'),'uncompressed'(不压缩),'producer'(保留producer的原始压缩) |
| delete.topic.enable | false | 如果false,通过admin 工具也不能删除topic。 |
| host.name | 废止 | listener没有设置时有效, 如果设置将会bind这个host,否则绑定0.0.0.0。 |
| listeners | string | 逗号隔开多个, 绑定的监听。PLAINTEXT://myhost:9092,SSL://:9091 CLIENT://0.0.0.0:9092,REPLICATION://localhost:9093 |
| leader.imbalance.check.interval.seconds | long(300) | controller检查分区再平衡的频率。 |
| leader.imbalance.per.broker.percentage | int(10) | 每个broker不平衡比例超过这个百分比就会触发leader再平衡。 |
| log.dirs | 保存kafka数据的目录。 | |
| log.dir | /tmp/kafka-logs | 补充log.dirs. |
| log.flush.interval.messages | 9223372036854775807 | 一个log分区累计消息条数到达该值时刷写到磁盘, 太小会使拷贝频繁,影响性能。 |
| log.flush.interval.ms | 消息从内存拷贝到磁盘的时间间隔,未设置时使用log.flush.scheduler.interval.ms | |
| log.flush.offset.checkpoint.interval.ms | int(60000) | 更新上次持久化消息(作为恢复点的消息)的频率。 |
| log.flush.scheduler.interval.ms | long(9223372036854775807) | log flusher检查log是否需要刷写到磁盘的频率。 |
| log.retention.bytes | long(-1) | log超过这个字节数之后就会被删除。 |
| log.retention.hours | int(168) | 超过改时间的log 文件会被删除。 |
| log.retention.minutes | int | 如果设置这个值,log.retention.hours就不会使用。 |
| log.retention.ms | long | 如果设置这个值,log.retention.minutes就不会使用。 |
| log.roll.hours | int(168) | 新建log文件的时间间隔。 |
| log.roll.ms | long | |
| log.segment.bytes | int(1073741824) | 单个log文件的最大字节数, 超过会新建文件。 |
| log.segment.delete.delay.ms | long(60000) | 等待从文件系统中删除一个文件的时间。 |
| message.max.bytes | int(1000012) | 服务器能接受的最大消息大小。 |
| min.insync.replicas | int(1) | 如果producer要求确认(参见producer参数acks),至少要有这么多的复制集回应写入成功,如果达不到,producer会提示异常(NotEnoughReplicas or NotEnoughReplicasAfterAppend) |
| num.io.threads | int(8) | 服务器用于执行网络请求的io线程数量。 |
| num.network.threads | int(3) | 服务器用于执行网络请求的网络线程数量。 |
| num.recovery.threads.per.data.dir | int(1) | 给每个目录生成的进程数,用于启动时的log恢复或者在shutdown时的log刷写。 |
| num.replica.fetchers | int(1) | 用来从source broker上复制消息的fetcher进程数量。太大会增加IO负担。 |
| offset.metadata.max.bytes | int(4096) | 关联一个offset commit 的 metadata条目的最大字节数。 |
| offsets.commit.required.acks | short(-1) | 一个commit被接受的必需acks数量,通常使用默认-1. |
| offsets.commit.timeout.ms | int(5000) | offset提交的时间限制,除非这个offsets topic的所有复制集收到提交或该时间到达。 |
| offsets.load.buffer.size | int(5242880) | 当从缓存加载offsets值时,从offsets segments读取的batch size。 |
| offsets.retention.check.interval.ms | long(600000)(10min) | 检查陈旧的offsets的频率。 |
| offsets.retention.minutes | int(1440) | offsets(其实也是一个topic)保留的时间。 |
| offsets.topic.compression.codec | int(0) | |
| offsets.topic.num.partitions | int(50) | offsets topic的默认分区数量。 |
| offsets.topic.replication.factor | short(3) | offsets topic的默认复制集个数, 高会更安全。 |
| offsets.topic.segment.bytes | int(104857600) | offsets 分段的大小,超过会新建文件。 |
| queued.max.requests | int(500) | 当网络进程阻塞时,允许的加入队列的请求数量。 |
| replica.fetch.min.bytes | int(1) | 每个期望的fetch响应比特数,如果未到等待时间replicaMaxWaitTimeMs. |
| replica.fetch.wait.max.ms | int(500) | follower向每个fetcher请求复制时等待相应的最大时间。这个值应该比replica.lag.time.max.ms小, 避免低流通的时候就出现ISR的频繁收缩。 |
| replica.high.watermark.checkpoint.interval.ms | long(5000) | |
| replica.lag.time.max.ms | long(10000) | 如果一个follower在这个时间内都没有向leader发送fetcher请求或者消费leader数据, **leader就会将其从ISR中剔除**。 |
| replica.socket.receive.buffer.bytes | int(65536) | socket接受网络请求的buffer |
| replica.socket.timeout.ms | int(30000) | 网络请求的socket延时,值应该不小于replica.fetch.wait.max.ms |
| request.timeout.ms | int(30000) | 客户端等待请求的最大时间,如果过了这段时间客户端没有得到请求,客户端有必要可以重发请求,或者定义为请求失败。 |
| socket.receive.buffer.bytes | int(102400) | |
| socket.request.max.bytes | int(104857600) | socket请求的最大字节数。 |
| socket.send.buffer.bytes | int(102400) | |
| unclean.leader.election.enable | bool(true) | |
| zookeeper.connect | ||
| zookeeper.connection.timeout.ms | int(null) | 客户端和zk建立链接的最长时间。未设置是使用 zookeeper.session.timeout.ms |
| zookeeper.session.timeout.ms | int(6000) | Zookeeper session timeout |
| zookeeper.set.acl | bool(false) | 设置client是否使用ACLs |
名词
日志聚合 log aggregation
日志聚合一般来说是从服务器上收集日志文件,然后放到一个集中的位置(文件服务器或 HDFS)进行处理。
页缓存 pagecache
将文件页缓存到内存中,方便下次直接从内存中读取。
- 文件 cache
本文中提到:"操作系统是计算机上最重要的系统软件,它负责管理各种物理资源,并向应用程序提供各种抽象接口以 便其使用这些物理资源。从应用程序的角度看,操作系统提供了一个统一的虚拟机,在该虚拟机中没有各种机器的具 体细节,只有进程、文件、地址空间以及进程间通信等逻辑概念。" 我对这里说的操作系统在应用层面上可以看做一个虚拟机的观点理解:操作系统是封装了对计算机硬件的使用该接口, 我们通过操作系统传达我们的需要给硬件而驱动计算机硬件的工作。我们要操作的实际是真是的物理机器,而直接操作 的是操作系统,所以从我们应用层面来说,操作系统就是物理机器的虚拟。
- 虚拟文件系统 VFS
虚拟文件系统(Virtual File System, 简称 VFS), 是 Linux 内核中的一个软件层,用于给用户空间的程序提供文 件系统接口;同时,它也提供了内核中的一个 抽象功能,允许不同的文件系统共存。系统中所有的文件系统不但依赖 VFS 共存,而且也依靠 VFS 协同工作。
reference
kafka在zk中的目录
zk中的目录结构和算法用于协调消费者和kafka节点。
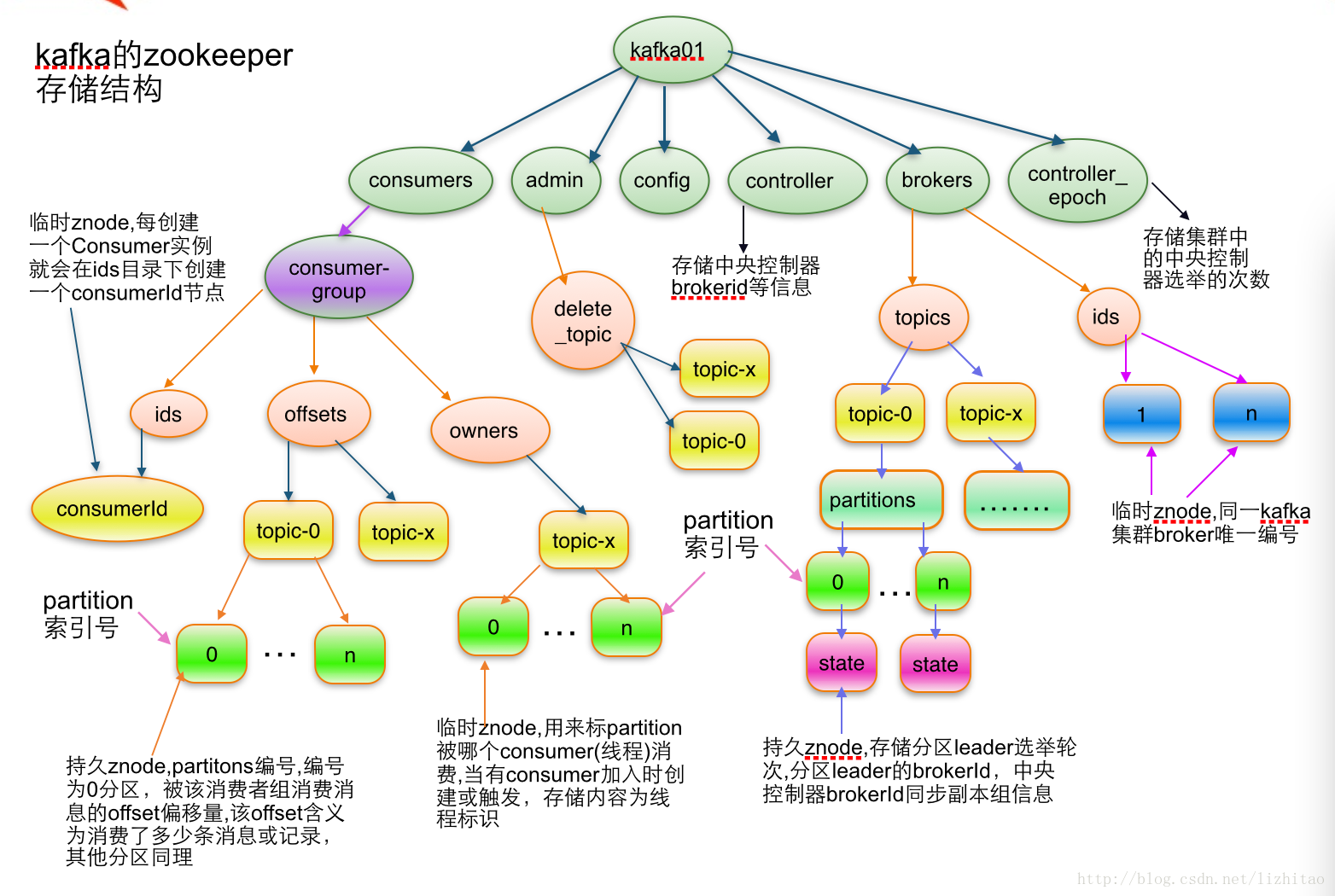
Figure 6: brokers in zk
[zk: 192.168.0.45:2181(CONNECTED) 40] ls / [cluster, controller_epoch, controller, brokers, zookeeper, kafka-manager, admin, isr_change_notification, consumers, config]
brokers注册
- 或者的brokers列表,唯一的id,消费者从这里获取broker的信息。
- brokers启动是注册(创建目录),shutdown和die时消失,消费者得到通知。(暂态的)
brokers上的topic注册
- 该broker上的topic信息。
- 也是暂态的。
- brokers/topics[topic]/partitions/[0...N]/state
consumer Id注册
- 协调彼此,均衡数据的消费
- 通过配置offsets.storage=zookeeper将offsets信息存在zookeepker上。但该机制会被废除,建议放到kafka上。
- consumer[group_id]/ids/[consumer_id], 暂态的,如果consumer挂了就会消失。
consumer offset
- consumers[group_id]/offsets/[topic]/[partition_id] --> offset_counter_value, 这个是永久值。
- 记录某个消费组消费某个topic的某个分区的offset。
分区消费者注册
- 一个分区只能被一个消费组的一个consumer消费。
- consumers[group_id]/owners/[topic]/[partition_id] --> consumer_node_id (ephemeral node)
- 该注册信息是暂态的,旧的consumer挂了,或者新增consumer,可能会均衡到其他consumer去消费。
Cluster Id
- /cluster/id
- 每个kafka cluster再zk上有一个唯一不变的集群id。这个id集群第一次启动后自动产生。broker启动后会从/cluster/id这个znode上获取,如果没有就新建。
Broker node 注册
- 前面broker下面的其实就是broker注册信息。
- broker本质上是独立的,他们只发布他们有点信息。
- 当一个新的broker加入集群,不仅会注册自己的,还会把broker上的topic信息也一起注册。
- 新的topic产生之后也会将topic的信息注册在broker下面。
消费者注册算法
步骤:
- 注册自己在/consumer/[group_id]/ids/[id]下,内容包括{"pattern":"static","subscription":{"intoyun-info-message":1},"timestamp":1494398431,"version":1}
- 在consumer id下注册注册一个watcher,监控消费者的加入或者移除的变化。每次变化都会触发组内消费者的重新均衡。
- 在broker id下注册一个watcher,监控broker的加入和移除,每次broker的变化都会触发所有消费组中所有consumer的重新均衡。
- 如果消费者创建了一个消息流(就是消费一个topic,又将处理后的数据发送另一个topic),他也会再broker id下注册一个watcher监控新加入的topic。进而触发可得topics的一些列动作。
- 强制消费组内的consumers重新均衡。
消费者再均衡算法
当出现broker的变化或者消费组内consumer的变化都会触发consumers的再均衡。对于一个给定的topic和已知的消费者,broker上的分区都会均衡的分配给组内的consumers消费。
一个分区只能被一个组内的消费者消费,这样简化了运用,否则,分区上还需要很多的锁。再均衡的时候,通过下面的方法将一个分区分配给消费者,这样可以减少每个消费者连接的broker个数:
- 对于消费者组CG=[C0, C1, ...,], topic的分区PT=[P0, P1,...];
- N = size(PT)/size(CG);(向上取整)
- 分配Ci消费i*N到(i+1)*N-1;
- 分配完之后删除当前的消费关系;
- 新加入分区之后重新均衡。
比如:10个分区[P0~P9],3个消费者[C0~C2]; N = 10/3=4, 那么: C0消费0*4~(0+1)*4-1,即0~3; C1消费1*4~(1+1)*4-1,即4~7; C2消费2*4~(2+1)*4-1,即8~11(8~9);
再比如:6个分区[P0~P5],5个消费者[C0~C4]; N = 6/5=2, 那么: C0消费0*2~(0+1)*2-1,即0~1; C1消费1*2~(1+1)*4-1,即2~3; C2消费2*2~(2+1)*4-1,即4~5; C3消费3*2~(3+1)*4-1,即empty; C4消费4*2~(4+1)*4-1,即empty;
这样就有两个worker占用资源但是闲置了。
因此:
- 按照如上的算法,所以如果kafka的消费组需要增加组员,最多增加到和partition数量一致,超过的组员只会占用资源,而不起作用;
- kafka的partition的个数一定要大于消费组组员的个数,并且partition的个数对于消费组组员取模一定要为0,不然有些消费者会占用资源却不起作用;
- 如果需要增加消费组的组员个数,那么也需要根据上面的算法,调整partition的个数
但是如果offset再zk上,以上规则不一定适合。
kafka broker的节点注册
保存或者的broker信息。
broker启动之后,会在zk上/brokers/ids目录下创建一个znode来注册自己的信息。每个broker都会提供一个唯一的逻辑id,消费者会识别这个id,并从这个获取到这个broker的基本配置。 这个逻辑Id的作用是broker被移动到另一个机器上之后,不会对消费者产生影响。如果注册的ID已经存在就会报错。
broker在zk上的注册信息是暂时的,一旦broker关闭或挂掉,这些注册信息就会消失,这样会告诉消费者该broker已经挂了。
如下: 这个znode的值包括:
| "listener_security_protocol_map" | {"PLAINTEXT":"PLAINTEXT"} |
| "endpoints" | ["PLAINTEXT://192.168.0.45:9093"] |
| "jmx_port" | 9999 |
| "host" | "192.168.0.45" |
| "timestamp" | "1494377317378" |
| "port" | 9093 |
| "version" | 4 |
[zk: 192.168.0.45:2181(CONNECTED) 6] get /brokers/ids/0
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://192.168.0.45:9093"],"jmx_port":9999,"host":"192.168.0.45","timestamp":"1494377317378","port":9093,"version":4}
cZxid = 0x50000000f
ctime = Wed May 10 08:48:37 CST 2017
mZxid = 0x50000000f
mtime = Wed May 10 08:48:37 CST 2017
pZxid = 0x50000000f
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x25befd4048b0001
dataLength = 196
numChildren = 0
broker topic的注册
brokers/topics[topic]/partitions/[0...N]/state --> {"controller_epoch":...,"leader":...,"version":...,"leader_epoch":...,"isr":[...]} (ephemeral node)
每个broker都会注册在该broker上的所有topic信息,包括topic,分区,每个分区的state,
references
- Apache Kafka Best Practices https://www.slideshare.net/HadoopSummit/apache-kafka-best-practices
- Kafka Best Practices https://community.hortonworks.com/articles/80813/kafka-best-practices-1.html
- How many topics can be created in Apache Kafka? https://www.quora.com/How-many-topics-can-be-created-in-Apache-Kafka
- 某互联网大厂kafka最佳实践 http://www.jianshu.com/p/8689901720fd